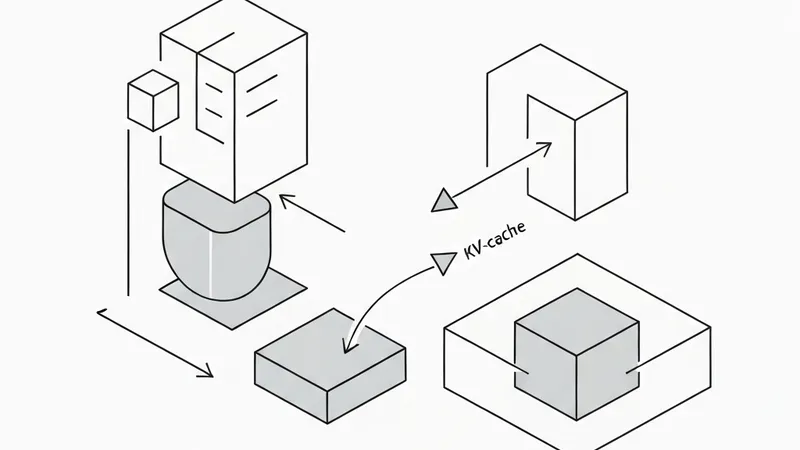
In #LLM #inference, the KV-cache is the single most critical optimization—and the reason real-time, fluid chat with a model is even feasible. Here is how it works and why it is indispensable.
To understand its role, we must note that text generation is inherently autoregressive. An LLM produces text one token at a time: it emits a token, appends it, and runs the entire model again. Within each attention layer, every token is converted into a Query, Key, and Value vector. Generating the newest token requires scoring its Query against the Keys of all prior tokens and blending their Values. Hence, producing token t requires the K and V of tokens 1 through t.
Without a cache, a naive approach results in quadratic complexity. Each step must completely re-encode the entire prefix to rebuild the K/V states. Step 1 processes 1 token, step 2 processes 2, and step N processes N. The total computation is roughly N(N+1)/2. This means token 1's K/V gets re-encoded at every single step, even though its value never changes.
The key insight here is that LLMs utilize causal masking, meaning a token only attends to earlier tokens. Consequently, appending a new token at the end cannot alter the Keys and Values of preceding tokens. They remain constant. Recomputing them is sheer computational waste.
By storing each token's K/V the first time it is calculated, we achieve linear generation. Each subsequent step computes K/V for only the single new token, appends it to the cache, and performs attention over the entire history. This brings the total complexity down to O(N) from O(N²).
This mechanism splits inference into two key phases: Prefill, where the entire prompt is ingested in one parallel pass to fill the cache (compute-heavy, explaining the slight delay before the first token), and Decode, where output tokens are generated one by one with cheap cache appends. This is why time to first token (TTFT) and time per output token are vastly different performance metrics.
However, long context comes with a severe memory price. The cache stores K and V for every token, layer, and head. Its size grows linearly with context length. A 128k-token context can consume gigabytes of GPU memory, restricting concurrency. To mitigate this, advanced techniques like PagedAttention (championed by vLLM), Grouped-Query Attention (GQA), cache quantization, and prompt caching have been developed.
[AgentUpdate Depth Analysis] The #KV-cache optimization effectively shifts the LLM inference bottleneck from compute-bound to memory-bound. As the AI Agent ecosystem transitions toward highly autonomous, multi-turn, and tool-using systems, context windows are expanding exponentially. Consequently, managing the massive memory footprint of the KV-cache has become the primary barrier to cost-effective Agent scaling. Future engineering breakthroughs will inevitably center on optimizing this cache. Innovations such as Prompt Caching, Grouped-Query Attention (GQA), and cache quantization are no longer just optional optimizations; they are foundational requirements. Solving the KV-cache bottleneck is critical to unlocking high-concurrency, low-latency, and economically viable Agent swarms.