As AI transitions from digital screens into the physical world, #multimodal models are undergoing a paradigm shift in architecture. Om AI has officially launched VLX, the world's first edge-side streaming multimodal model series specifically designed for physical intelligence.
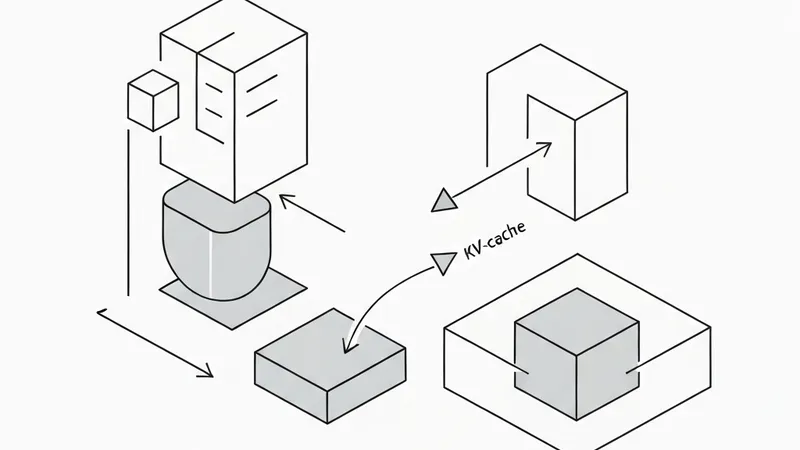
Unlike traditional video understanding models that process pre-sliced offline video frames in batches, the VLX series handles incoming real-time video streams. It utilizes streaming encoding and incremental cache inference to achieve millisecond-level perception, bridging the gap between "continuous perception, precise localization, and immediate action" entirely on-device.
The VLX series consists of three specialized models that form a complete physical intelligence system:
1. VLX-Flow is responsible for continuous perception. Utilizing incremental encoding and cache inference, it observes environments proactively rather than waiting for user prompts, updating internal states in real-time and replying instantly.
2. VLX-Seek focuses on precise localization, innovatively converting coordinate generation into region retrieval. By "selecting" from candidate areas rather than "predicting" precise pixel coordinates, it ensures highly reliable spatial awareness on resource-constrained edge devices.
3. VLX-Go executes physical actions, directly converting visual inputs into short-term waypoints and motion trajectories for robotic control instead of generating text suggestions, enabling autonomous tracking, obstacle avoidance, and navigation.
Under this new framework, visual data feeds into the model as a continuous stream. Rather than "waiting to see the whole clip," the model processes and understands information on the fly, translating it into action when necessary. This shift unlocks true autonomy for physical agents rather than just offering a better chat-based UI.
To survive under physical constraints—continuous time, dynamic environments, and limited edge compute—VLX was built from scratch for on-device deployment. It is not a compressed version of a cloud model but a native architecture for edge intelligence, offering speed (latencies as low as 0.06s), small footprints (spanning 0.6B to 10B parameters), high precision, and complete perception-action loops.
[AgentUpdate Depth Analysis] Most current Vision-Language Models (VLMs) rely on passive offline frame processing, which is highly inefficient for dynamic physical environments. Om AI’s VLX introduces a paradigm shift towards "streaming multimodality," fundamentally re-engineering the sensory system of embodied AI Agents. By shrinking latency to a mere 0.06 seconds and generating direct physical trajectories instead of abstract text, VLX bridges the gap between reasoning and execution. Delivering this capability on-device within a 0.6B to 10B parameter footprint solves critical bottlenecks in edge compute and privacy. This advancement will accelerate the deployment of real-world AI Agents across #robotics and spatial computing, marking a crucial transition from static chat assistants to proactive, physical-world actors.