The KV-cache is the single most important optimization in LLM inference — and the fundamental reason real-time interactive chat with a model is even feasible. Here is a deep dive into how it works and why it matters.
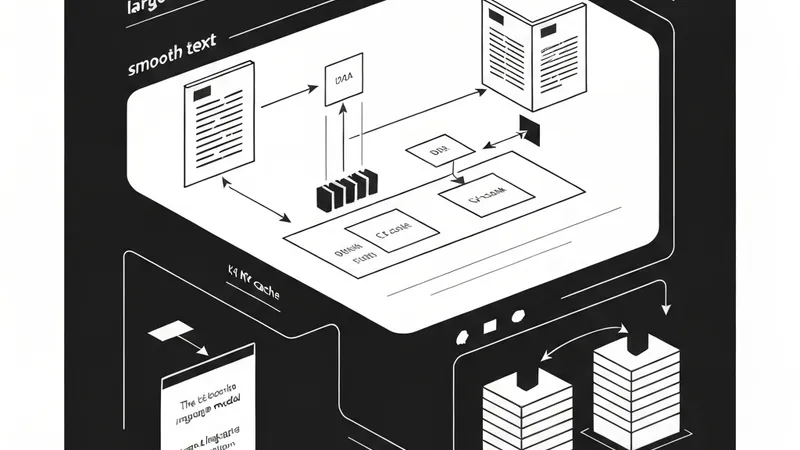
LLM text generation is inherently autoregressive: the model produces text one token at a time. It emits a token, appends it to the prompt, and runs the entire model again to generate the next one. Inside each attention layer, every token is represented as a Query, a Key, and a Value. To produce the newest token, its Query is scored against the Keys of all previous tokens, blending their Values. Thus, generating token t requires the K and V vectors of tokens 1 to t.
Without caching, the naive approach results in quadratic complexity. Each step re-encodes the entire prefix to rebuild K/V for all previous tokens. Step 1 processes 1 token, step 2 processes 2, and step N processes N tokens. The total computational work scales as N(N+1)/2, which is O(N²). Even though the K/V values of previous tokens never change, they are wastefully recomputed on every single step.
The key insight lies in causal masking: an LLM token only attends to earlier tokens. Adding a new token at the end cannot change the Keys and Values of preceding tokens; they remain constant. By caching each token's K/V upon its first computation, we achieve linear generation. Each subsequent step only computes K/V for the single new token, appends it to the cache, and performs attention over the accumulated history, converting the per-step work to constant O(1) and the total complexity to O(N).
This mechanism splits LLM inference into two distinct phases: Prefill and Decode. Prefill ingests the entire prompt in one parallel pass to fill the cache (compute-heavy, explaining the initial pause for long prompts). Decode generates output tokens sequentially, utilizing cheap cache-appends. This explains why Time to First Token (TTFT) and time-per-output-token represent vastly different performance characteristics.
However, long context windows come with a steep GPU memory cost. The cache size scales linearly with context length, storing K/V for every token, layer, and attention head. This is why 128k-token contexts are incredibly resource-intensive, consuming gigabytes of GPU memory and limiting serving capacity. Solutions like PagedAttention (#vLLM), Grouped-Query Attention (GQA), quantized caches, and prompt caching are essential to mitigate this memory bottleneck.
[AgentUpdate Depth Analysis] The evolution of #KV-cache management is critical for the scalability of AI Agents. Agentic workflows rely heavily on iterative loops, dense system prompts, and tool descriptions that must be re-evaluated continuously. Without advanced KV-cache sharing and optimization, the high latency and cost of multi-turn tool interactions would render complex Agents impractical. Techniques like Prompt Caching (now widely adopted by Anthropic and OpenAI) allow Agents to reuse pre-computed context, slashing both costs and TTFT. In the long run, hardware-efficient cache storage and dynamic compression are not just minor infrastructure tweaks, but foundational enablers that allow AI Agents to operate with persistent, long-term memory in real-time environments.