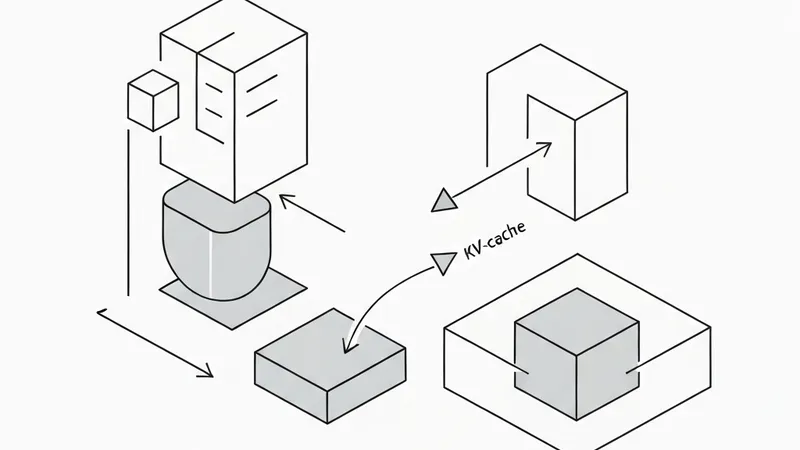
每一个 Claude Code 的资深用户可能都有过类似的惊险经历:Agent 不小心强制推送(force-push)到了 master 主分支,或者非常“贴心”地重写了含有机密的 .env 文件,再或者是凌晨两点把 API 密钥提交到了公开仓库。其实,解决这个痛点的方案一直写在官方文档里,那就是——hooks(钩子)。这些是在模型外部运行的 Shell 脚本,即使大模型“状态不佳”出现幻觉,这些钩子依然能死死守住底线。
然而,编写防御性的 Hook 脚本确实相当繁琐,导致很少有人真正去配置它们。在构建了一整套包含 10 个安全防线钩子的过程中,有三个最核心的运行机制需要特别注意:
首先,Exit code 2 是最关键的魔法值。如果一个 PreToolUse 钩子以退出码 2 结束,它就会直接拦截这次工具调用,并且你在 stderr(标准错误)中写入的任何内容,都会作为“拦截原因”反馈给 Claude。大模型在收到反馈后会立刻调整行为——例如你告诉它“拒绝强推至主分支,请使用功能分支”,它就会乖乖照做。而普通的退出码 0 表示允许执行,其他退出码则仅仅进行日志记录。
其次,使用 JSON 决策比单纯的退出码更为细腻。在 stdout(标准输出)上打印类似 {"decision":"block","reason":"..."} 的 JSON 格式内容可以起到相同的拦截作用,这也同样适用于 PostToolUse 钩子的反馈循环。例如,你可以借此将 Linter 的报错信息直接导回给模型,实现 Agent 自我修复代码警告的闭环。
最后,Stop hook(停止钩子)可以拒绝 Agent 的“收工”申请。如果一个 Stop 钩子运行了你的测试集且返回红色的失败结果,Agent 就无法在测试未通过的情况下宣告任务完成。为了防止出现因反复重试导致的死循环,你需要在 Payload 中检查 stop_hook_active 状态。
在设计这些高可信度的钩子时,有四个黄金法则:
1. 故障放行(Fail open):如果缺少 jq 依赖或者脚本自身报错,应当允许操作继续。一个经常导致整个会话卡死崩溃的防线,只会被用户在午饭前彻底卸载。
2. 带指导地阻拦(Block with instructions):stderr 里的报错信息本质上就是给模型的 Prompt。不要只生硬地回一句“不行”,要告诉模型接下来该怎么做。
3. 提供一键关闭开关:设置 REPO_ARMOR_DANGER_OFF=1 这类环境变量,远比在紧急线上排障时临时去修改 settings.json 优雅得多。
4. 精准匹配,避免误伤:例如,拦截 rm -rf / 的 Bash 匹配器必须放行 rm -f build/tmp.txt,否则过于高频的误报会逼你关掉整个防护系统。
一套真正实用的 10 个安全钩子组合应该涵盖:密钥泄露拦截器、危险命令防御、受保护文件守卫、主分支提交限制、停止时强制测试、编辑时自动格式化、Lint 反馈循环、桌面通知提醒、JSONL 审计日志,以及当 Prompt 提及“生产环境(production)”时自动注入警告的上下文守卫。你可以基于上述机制自行编写,或者使用封装好的开源工具 repo-armor。无论哪种方式,在让 Agent 进行长时间自主运行之前,请务必先扣好这条安全带。
在当前的 AI Agent 领域,如 LangGraph、CrewAI 等框架多依赖于大模型自身的“反思(Reflection)”机制或内部 Guardrails 来纠错。然而,这种“端到端”的黑盒控制极易因模型幻觉而失效。Anthropic 引入的 Claude Code hooks 机制,本质上是在 AgentOS 层面引入了“非对称硬控制”。它通过在模型外部执行原生 Shell 脚本,以确定性的软件工程逻辑(如编译检查、Git 规则、安全扫描)强行约束不确定性的 AI 行为。这种“安全带”设计为未来 Agent 生态确立了标杆:AI 可以自主思考,但执行权的最终闸口必须牢牢掌控在传统确定性系统的 Hook 中。这不仅能杜绝越权和毁灭性操作,更是 AI Agent 迈向严肃生产环境的必经之路。